Code
"""
Entering code into this notebook cell
and pressing [SHIFT-ENTER] will cause the
python interpreter to execute the code
"""
print("Hello world!")
print("[from this notebook cell]")Hello world!
[from this notebook cell]Course Repository: https://github.com/environmental-data-science/eds217_2023
Course Website: https://bit.ly/eds217_2023


“Python is powerful… and fast; plays well with others; runs everywhere; is friendly & easy to learn; is Open.”
Python is a general-purpose, object-oriented programming language that emphasizes code readability through its generous use of white space. Released in 1989, Python is easy to learn and a favorite of programmers and developers.
(Python, C, C++, Java, Javascript, R, Pascal) - Take less time to write - Shorter and easier to read - Portable, meaning that they can run on different kinds of computers with few or no modifications.
The engine that translates and runs Python is called the Python Interpreter
"""
Entering code into this notebook cell
and pressing [SHIFT-ENTER] will cause the
python interpreter to execute the code
"""
print("Hello world!")
print("[from this notebook cell]")Hello world!
[from this notebook cell]"""
Alternatively, you can run a
any python script file (.py file)
so long as it contains valid
python code.
"""
!python hello_world.pyHello world!
[from hello_world.py]Natural languages are the languages that people speak. They are not designed (although they are subjected to various degrees of “order”) and evolve naturally.
Formal languages are languages that are designed by people for specific applications. - Mathematical Notation E=mc^2 - Chemical Notation: \text{H}_2\text{O}
Programming languages are formal languages that have been designed to express computations.
Parsing: The process of figuring out what the structure of a sentence or statement is (in a natural language you do this subconsciously).
Formal Languages have strict syntax for tokens and structure:
The inherent differences between familiar natural languages and unfamiliar formal languages creates one of the greatest challenges in learning to code.
Python is a multi-purpose language with a readable syntax that’s easy to learn. Programmers use Python to delve into data analysis or use machine learning in scalable production environments.
R is built by statisticians and leans heavily into statistical models and specialized analytics. Data scientists use R for deep statistical analysis, supported by just a few lines of code and beautiful data visualizations.
In general, R is better for initial exploratory analyses, statistical analyses, and data visualization.
In general, Python is better for working with APIs, writing maintainable, production-ready code, working with a diverse array of data, and building machine learning or AI workflows.
Both languages can do anything. Most data science teams use both languages. (and others too.. Matlab, Javascript, Go, Fortran, etc…)
from IPython.lib.display import YouTubeVideo
YouTubeVideo('MkNnAwkvvP8')Anaconda State of Data Science
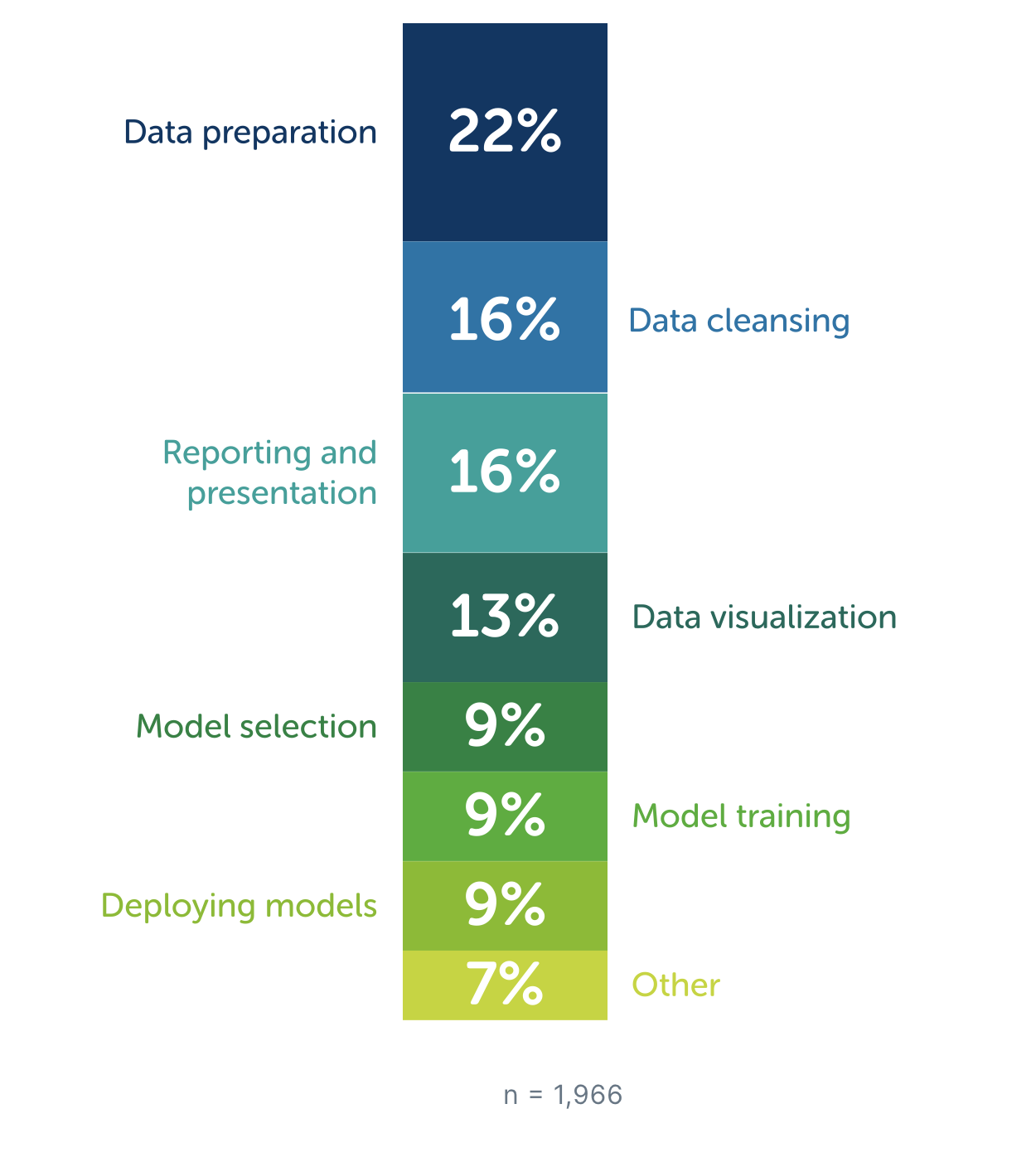
Data from 2021: 
The data are available here…
Let’s do some python data science!
# First, we need to gather our tools
import pandas as pd # This is the most common data science package used in python!
import matplotlib.pyplot as plt # This is the most widely-used plotting package.
import requests # This package helps us make https requests
import io # This package is good at handling input/output streams# Here's the url for the 2022 data that we just looked at:
url = "https://static.anaconda.cloud/content/Anaconda_2022_State_of_Data_Science_+Raw_Data.csv"
# Try to access the file using the requests library
response = requests.get(url)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
# A 200 response code means our request was successful:
print(response)<Response [200]># Read the response into a dataframe, using the io.StringIO function to feed the response.txt.
# Also, skip the first three rows
df = pd.read_csv(io.StringIO(response.text), skiprows=3)
# Our very first dataframe!
df.head()
# Jupyter notebook cells only output the last value requested...| In which country is your primary residence? | Which of the following age groups best describes you? | What is the highest level of education you've achieved? | Gender: How do you identify? - Selected Choice | The organization I work for is best classified as a: | What is your primary role? - Selected Choice | For how many years have you been in your current role? | What position did you hold prior to this? - Selected Choice | How would you rate your job satisfaction in your current role? | What would cause you to leave your current employer for a new job? Please select the top option besides pay/benefits. - Selected Choice | ... | What should an AutoML tool do for data scientists? Please drag answers to rank from most important to least important. (1=most important) - Help choose the best model types to solve specific problems | What should an AutoML tool do for data scientists? Please drag answers to rank from most important to least important. (1=most important) - Speed up the ML pipeline by automating certain workflows (data cleaning, etc.) | What should an AutoML tool do for data scientists? Please drag answers to rank from most important to least important. (1=most important) - Tune the model once performance (such as accuracy, etc.) starts to degrade | What should an AutoML tool do for data scientists? Please drag answers to rank from most important to least important. (1=most important) - Other (please indicate) | What do you think is the biggest problem in the data science/AI/ML space today? - Selected Choice | What tools and resources do you feel are lacking for data scientists who want to learn and develop their skills? (Select all that apply). - Selected Choice | How do you typically learn about new tools and topics relevant to your role? (Select all that apply). - Selected Choice | What are you most hoping to see from the data science industry this year? - Selected Choice | What do you believe is the biggest challenge in the open-source community today? - Selected Choice | Have supply chain disruption problems, such as the ongoing chip shortage, impacted your access to computing resources? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | United States | 26-41 | Doctoral degree | Male | Educational institution | Data Scientist | 1-2 years | Data Scientist | Very satisfied | More flexibility with my work hours | ... | 4.0 | 2.0 | 5.0 | 6.0 | A reduction in job opportunities caused by aut... | Hands-on projects,Mentorship opportunities | Reading technical books, blogs, newsletters, a... | Further innovation in the open-source data sci... | Undermanagement | No |
| 1 | United States | 42-57 | Doctoral degree | Male | Commercial (for-profit) entity | Product Manager | 5-6 years | NaN | Very satisfied | More responsibility/opportunity for career adv... | ... | 2.0 | 5.0 | 4.0 | 6.0 | Social impacts from bias in data and models | Tailored learning paths | Free video content (e.g. YouTube) | More specialized data science hardware | Public trust | Yes |
| 2 | India | 18-25 | Bachelor's degree | Female | Educational institution | Data Scientist | NaN | NaN | NaN | NaN | ... | 1.0 | 4.0 | 2.0 | 6.0 | A reduction in job opportunities caused by aut... | Hands-on projects,Mentorship opportunities | Reading technical books, blogs, newsletters, a... | Further innovation in the open-source data sci... | Undermanagement | I'm not sure |
| 3 | United States | 42-57 | Bachelor's degree | Male | Commercial (for-profit) entity | Professor/Instructor/Researcher | 10+ years | NaN | Moderately satisfied | More responsibility/opportunity for career adv... | ... | 1.0 | 5.0 | 4.0 | 6.0 | Social impacts from bias in data and models | Hands-on projects | Reading technical books, blogs, newsletters, a... | New optimized models that allow for more compl... | Talent shortage | No |
| 4 | Singapore | 18-25 | High School or equivalent | Male | NaN | Student | NaN | NaN | NaN | NaN | ... | 4.0 | 2.0 | 3.0 | 6.0 | Social impacts from bias in data and models | Community engagement and learning platforms,Ta... | Reading technical books, blogs, newsletters, a... | Further innovation in the open-source data sci... | Undermanagement | Yes |
5 rows × 120 columns
# Read the response into a dataframe, using the io.StringIO function to feed the response.txt.
# Also, skip the first three rows
df = pd.read_csv(io.StringIO(response.text), skiprows=3)
# Our very first dataframe!
df.head()
# Jupyter notebook cells only output the last value... unless you use print commands!
print(f'Number of survey responses: {len(df)}')
print(f'Number of survey questions: {len(df.columns)}')Number of survey responses: 3493
Number of survey questions: 120# 1. Filter the dataframe to only the questions about programming language usage, and
filtered_df = df.filter(like='How often do you use the following languages?').copy() # Use copy to force python to make a new copy of the data, not just a reference to a subset.
# 2. Rename the columns to just be the programming languages, without the question preamble
filtered_df.rename(columns=lambda x: x.split('-')[-1].strip() if '-' in x else x, inplace=True)# Calculate the percentage of each response for each language
percentage_df = filtered_df.apply(lambda x: x.value_counts(normalize=True).fillna(0) * 100).transpose()
# Remove the last row, which is the "Other" category
percentage_df = percentage_df[:-1]
# Sort the DataFrame based on the 'Always' responses
sorted_percentage_df = percentage_df.sort_values(by='Always', ascending=True)# Let's get ready to plot the 2022 data...
from IPython.display import display
# We are going to use the display command to update our figure over multiple cells.
# This usually isn't necessary, but it's helpful here to see how each set of commands updates the figure
# Define the custom order for plotting
order = ['Always', 'Frequently', 'Sometimes', 'Rarely', 'Never']
colors = {
'Always': (8/255, 40/255, 81/255), # Replace R1, G1, B1 with the RGB values for 'Dark Blue'
'Frequently': (12/255, 96/255, 152/255), # Replace R2, G2, B2 with the RGB values for 'Light Ocean Blue'
'Sometimes': (16/255, 146/255, 136/255), # and so on...
'Rarely': (11/255, 88/255, 73/255),
'Never': (52/255, 163/255, 32/255)
}# Make the plot
fig, ax = plt.subplots(figsize=(10, 7))
sorted_percentage_df[order].plot(kind='barh', stacked=True, ax=ax, color=[colors[label] for label in order])
ax.set_xlabel('Percentage')
ax.set_title('Frequency of Language Usage, 2022',y=1.05)
plt.show() # This command draws our figure. 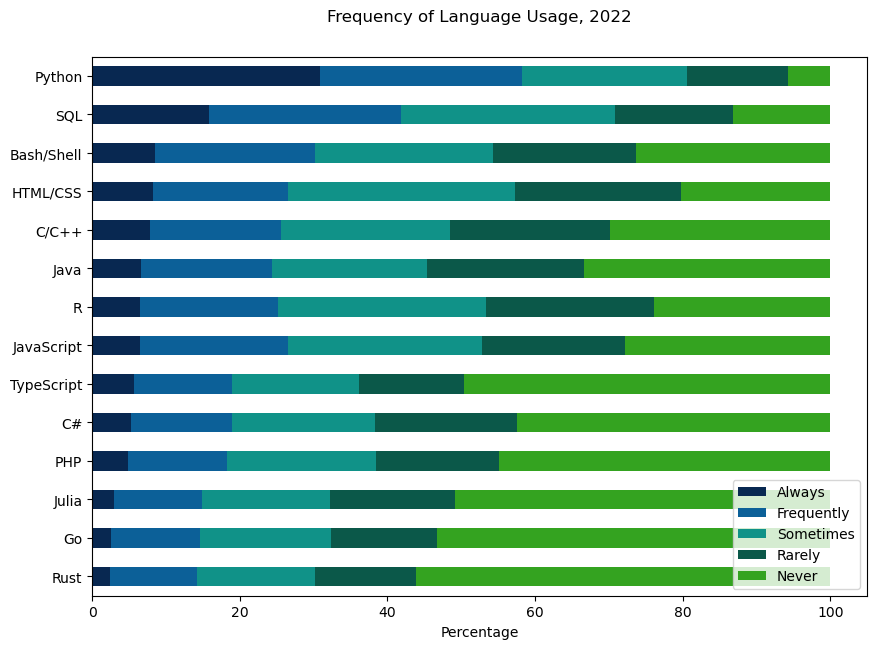
# Add labels across the top, like in the original graph
# Get the patches for the top-most bar
num_languages = len(sorted_percentage_df)
patches = ax.patches[num_languages-1::num_languages]
# Calculate the cumulative width of the patches for the top-most bar
cumulative_widths = [0] * len(order)
widths = [patch.get_width() for patch in patches]
for i, width in enumerate(widths):
cumulative_widths[i] = width + (cumulative_widths[i-1] if i > 0 else 0)
# Add text labels above the bars
for i, (width, label) in enumerate(zip(cumulative_widths, order)):
# Get the color of the current bar segment
# Calculate the position for the text label
position = width - (patches[i].get_width() / 2)
# Add the text label to the plot
# Adjust the y-coordinate for the text label
y_position = len(sorted_percentage_df) - 0.3 # Adjust the 0.3 value as needed
ax.text(position, y_position, label, ha='center', color=colors[label], fontweight='bold')
# Remove the legend
ax.legend().set_visible(False)
#plt.show()
display(fig) # This command shows our updated figure (we can't re-use "plt.show()")
# Add percentage values inside each patch
for patch in ax.patches:
# Get the width and height of the patch
width, height = patch.get_width(), patch.get_height()
# Calculate the position for the text label
x = patch.get_x() + width / 2
y = patch.get_y() + height / 2
# Get the percentage value for the current patch
percentage = "{:.0f}%".format(width)
# Add the text label to the plot
ax.text(x, y, percentage, ha='center', va='center', color='white', fontweight='bold')
display(fig) # Let's see those nice text labels!
# Clean up the figure to remove spines and unecessary labels/ticks, etc..
# Remove x-axis label
ax.set_xlabel('')
# Remove the spines
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
# Remove the y-axis tick marks
ax.tick_params(axis='y', which='both', length=0)
# Remove the x-axis tick marks and labels
ax.tick_params(axis='x', which='both', bottom=False, top=False, labelbottom=False)
display(fig) # Now 100% less visually cluttered!

Data is here
Writing code requires an editor.
Running code requires an interpreter.
How you setup your editor and your interpreter can vary widely…
By end of this course, you will have the ability to develop maintanable, repeatable python code that anyone can use!